
How to standardize dietary intake in ESM / EMA using structured dropdowns.
TL;DR
Experience sampling (ESM) / ecological momentary assessment (EMA) already improves dietary research by reducing recall bias and capturing eating behavior close to real time. But most studies still rely on open-ended food reports, which introduces inconsistency. Standardizing input at the moment of entry, for example using dropdown structures, turns real-time data into comparable and actionable data across participants and over time, enabling everything from basic logging to real-time interventions.
Experience sampling Methodology (ESM) / ecological momentary assessment (EMA) has drastically changed how we study eating behavior.
Instead of asking people what they ate today trough 24-hour food diaries, or to estimate food intake via general via food frequency questionnaires, we can now assess diet behavior as it unfolds in daily life.
That shift matters. It reduces reliance on memory, captures context, and gives a much more ecologically valid picture of what people actually eat.
But there may be a misconception hidden in this progress:
Real-time data is often assumed to be reliable data.But is this the case? 🤔
Same entry, but different realities
Let’s consider three ESM / EMA participants who report the same meal: “pasta with meat and vegetables.”🥗
- One means a small ready-made portion bought from a take-away restaurant.
- Another person refers to a large home-cooked dinner with fresh ingredients.
- A third individual forgets to mention the drink, side dishes or sauces.
Same label. Different food intake.
Even when reports are collected in real time, the way people describe what they eat varies. Some participants report in broad categories, while others list detailed ingredients. Portion sizes are rarely standardized, and even the definition of what counts as a “meal” can vary. Differences in how people describe their meals quietly introduces noise into your dataset.

different types of food intake may have the same entry "pasta with meat and vegetables".
Food researchers have become well aware of this issue, and many have explored alternatives. Some rely on photos of meals, voice annotations, or even short videos to capture richer information.
And in some respects, these approaches do improve data quality. But they share another critical limitation that is often overlooked.
They still require interpretation after the data is collected.
A photo needs to be coded. A voice note needs to be transcribed. A free-text entry needs to be standardized.
This means that the structure of the data is not defined during collection, but imposed afterwards. In a way, you are postponing the moment of comparability.
Why postponing structure is a problem
Delaying structure introduces two fundamental issues.
First, it creates inconsistency in how raw input is translated into variables. Even with clear coding schemes, interpretation can vary across coders, algorithms, or time.
Second, it limits what you can do with the data in real time.
If your data needs to be processed before it becomes usable, you cannot:
- Compare participants immediately
- Compute indicators on the fly
- Provide feedback in the moment
In other words, you lose one of the core advantages of ESM / EMA: its real-time nature.
Rich dropdowns provide structure at the moment of entry
What if you did not need to interpret data after collection? If it was already structured the moment it was entered?
This is where dropdown-based input comes into play.
Instead of asking participants to freely describe what they eat, you provide a structured selection system. In m-Path, this is typically defined via a simple CSV file that acts as the backbone of the input.
Each row represents a food item. Additional columns can include:
- Portion type (e.g., portion, scoop, gram)
- Caloric values
- Food categories (e.g., fruits, snacks, vegetables)
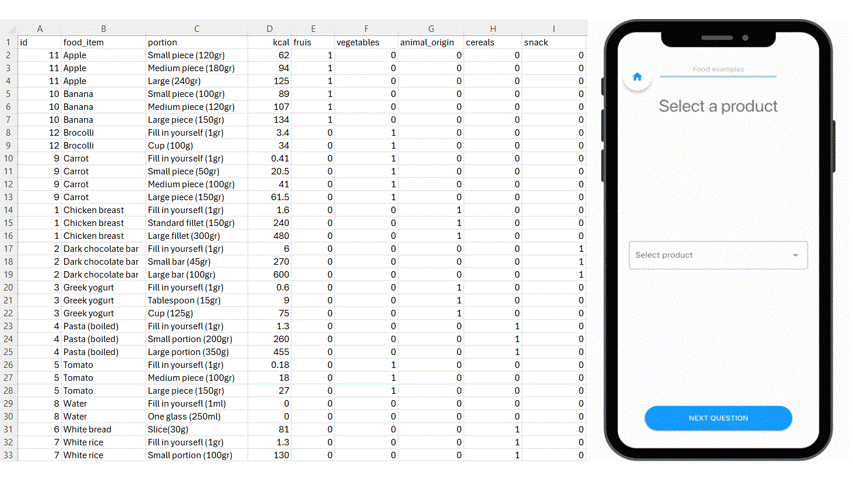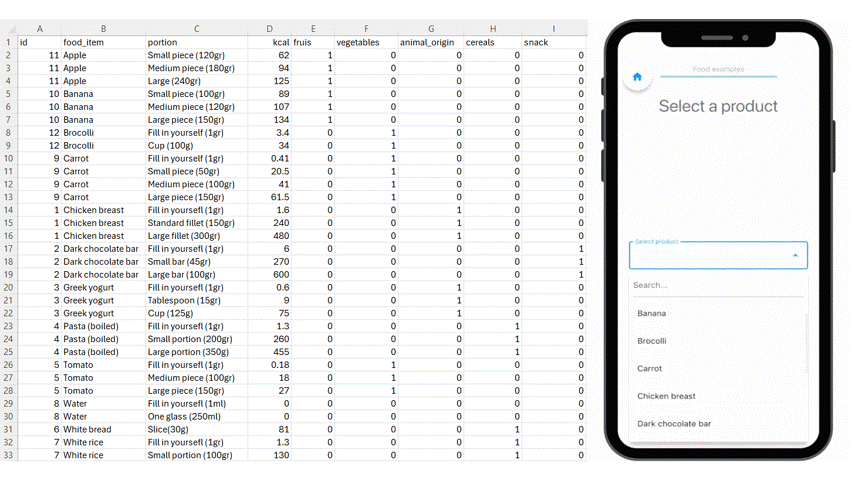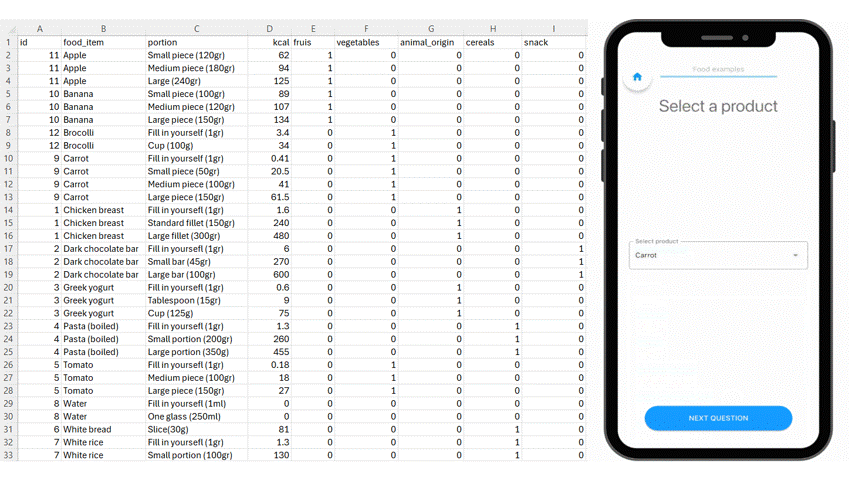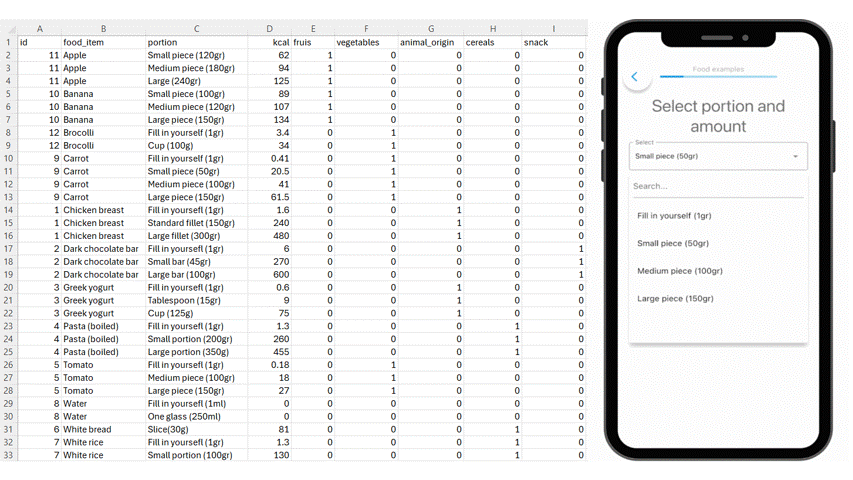
Upload a structured CSV file in m-Path to define the individual options in the dropdown item.
Participants are no longer describing their meals. They are selecting from a shared, predefined structure. When input is standardized at the source:
- A portion of pasta means the same thing for every participant.
- Caloric values are attached automatically
- Food categories are consistent across entries.
Data becomes comparable immediately. Not after cleaning or coding.
What this enables in practice
Once your data is structured from the start, entirely new possibilities open up. The key difference is that you are no longer working with descriptions that need interpretation, but with data that is immediately usable.
1. Standardized intake logging
At the most basic level, structured input gives you clean and consistent dietary logs.
Participants select from the same categories, use the same units, and follow the same structure. What looks identical in your dataset now actually represents comparable intake behavior.
This may sound simple, but it solves one of the core problems in dietary EMA / ESM: you are no longer comparing apples 🍏 with oranges🍊 (pun intended😊).
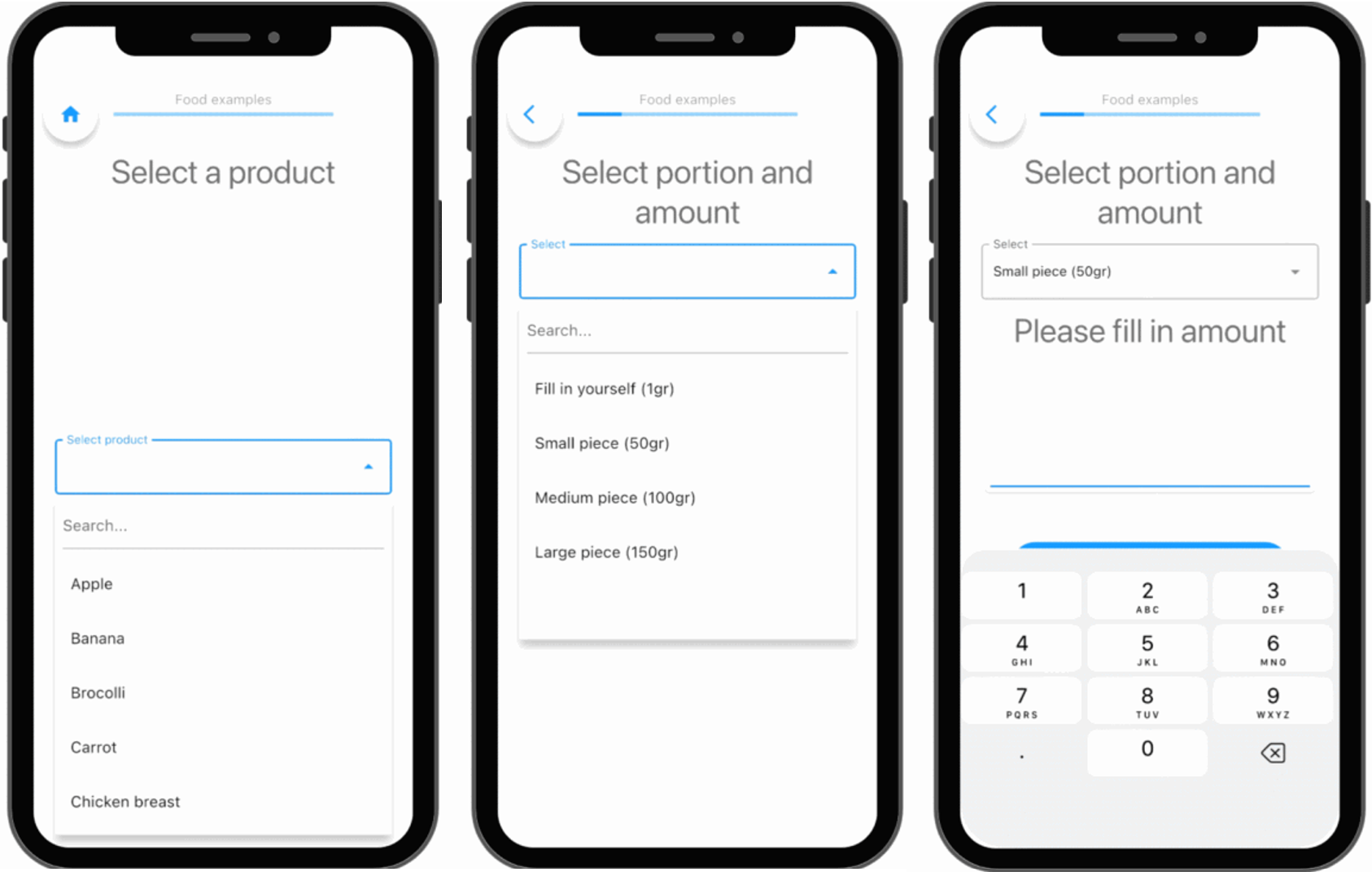
Logging standardized dietary products, portions and amount in the m-Path app.
2. Automatic computation of intake
Once portion sizes and caloric values are embedded in your input structure, your data becomes immediately computable (if you use the output of a CSV item in a computation item).
You can compute daily caloric intake automatically, without reconstructing meals after the fact. There is no need for manual coding or post-hoc estimation. The data is already in a format that can be aggregated and analyzed on participants' smartphone.
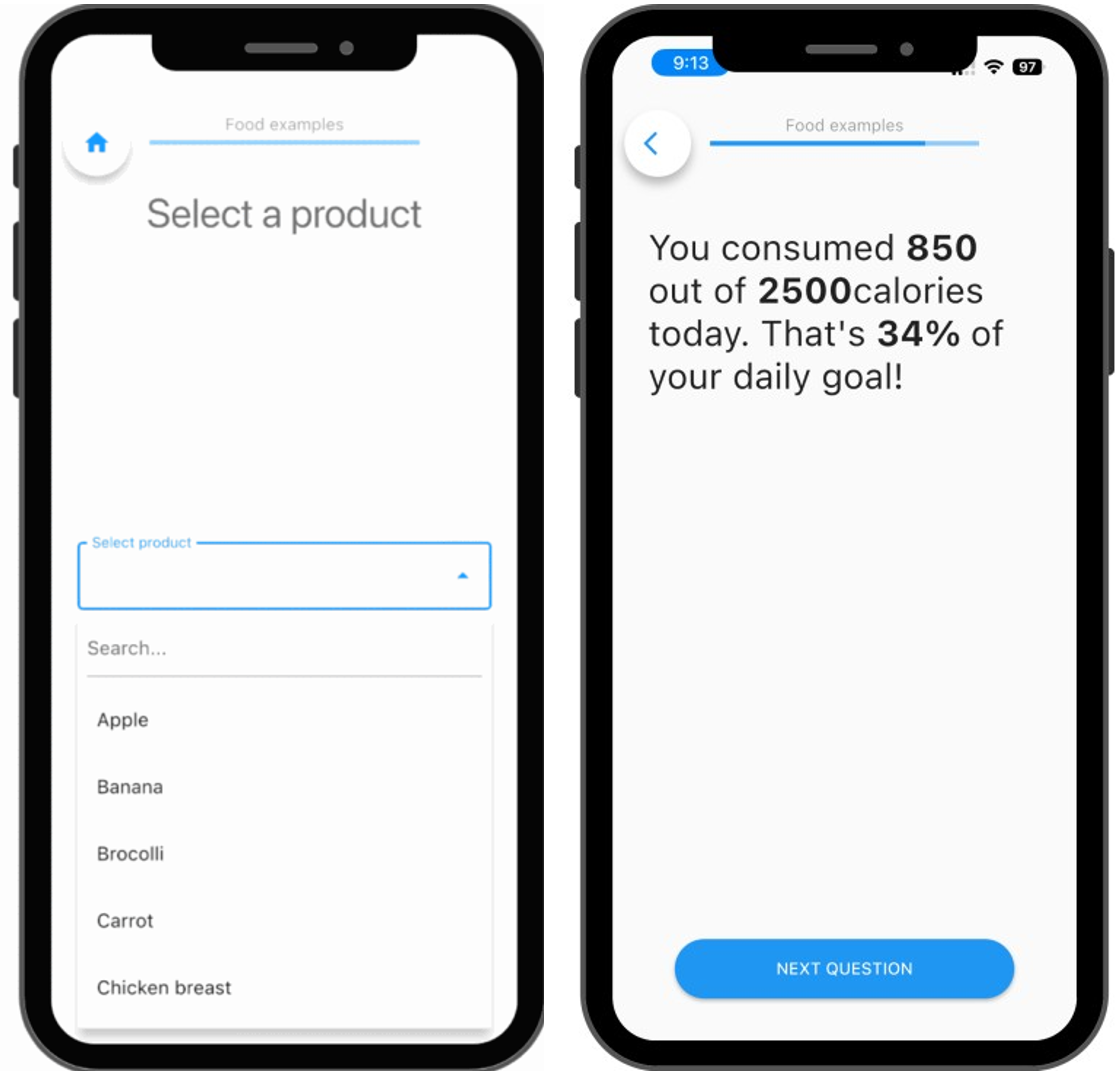
counting calories in the m-path app.
3. Tracking dietary patterns and balance
By encoding food categories, you move beyond single meals and start capturing patterns on the fly.
You can track dietary diversity and balance over time, identifying whether participants rely on a narrow set of foods or maintain a varied diet. This allows you to study food-related behavior and intake at a higher level, without losing the momentary detail that EMA / ESM provides.
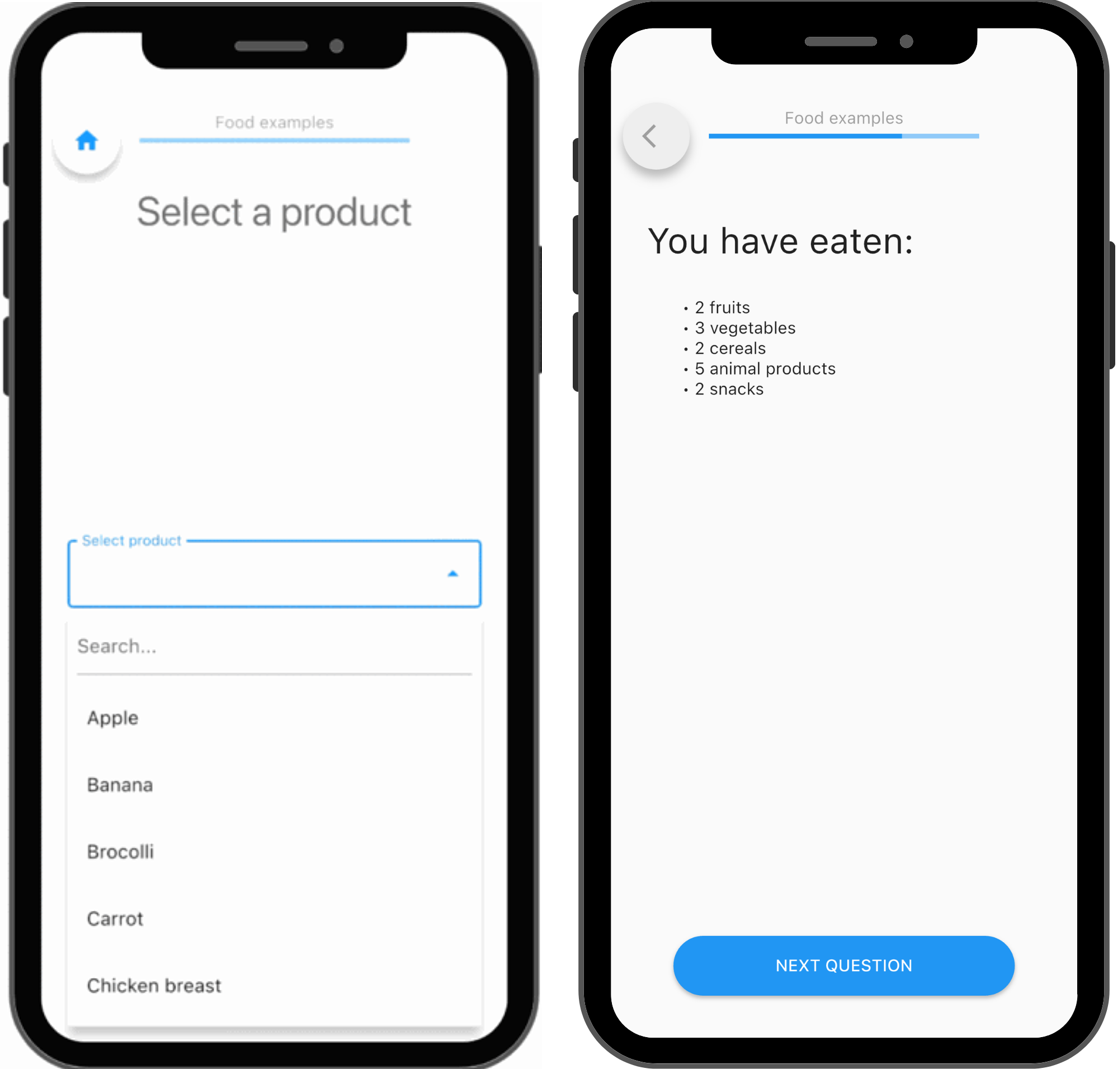
tracking dietary balance in the m-path app.
4. Real-time feedback and intervention
Perhaps the most important shift is what happens in real time.
Because the data is already structured, it can be interpreted immediately. This means you can detect patterns as they emerge and respond to them in the moment.
If a participant has not consumed vegetables throughout the day, the system can pick this up. If intake exceeds certain thresholds, this can be flagged. If a healthy choice is made, it can be reinforced right away.
This is where EMA / ESM moves beyond measurement. It becomes a tool for intervention in daily life.

Instantaneously reward certain intake behavior in the m-path app.
Why this matters for your research
How you measure shapes what you can learn. It is easy to think of input format as a technical detail. Something you decide late in the design process.
In reality, it is one of the most consequential choices you make.
If your input is unstructured, you are committing to:
❌ Post-hoc cleaning
❌ Interpretation ambiguity
❌ Limited real-time use
If your input is structured, you are enabling:
✅ Immediate comparability
✅ Direct computation
✅ Real-time analysis and feedback
If variability is not captured at entry, it cannot be reconstructed later. Food for thought (ok, last food-related pun 😅!).
In m-Path, you can define dropdown-based dietary input using a simple CSV structure. This allows you to standardize responses, attach metadata such as calories or food categories, and unlock real-time computation and feedback.
Check out our dedicated manual page to learn how to implement structured dropdown input in your ESM / EMA study.